
一、引言:保险与数学的千年羁绊
保险,作为一种分散风险、补偿损失的经济制度,与数学有着千丝万缕的联系,这种联系贯穿了人类历史的长河。甚至我们可以认为,正是人类对数学的不懈追求与研究,才能促成保险的产生并促进保险的发展。保险,由于拥有数学的基因,把不确定的风险量化定性,成为一门风险管理的科学。
早在公元前2000年,地中海地区的航海商人在遭遇海难时,为了避免船只和货物同归于尽,往往会抛弃部分货物,损失由各方共同承担,这便是共同海损分摊原则的雏形,也是保险思想的萌芽。而这一原则的实施,需要对货物价值、损失程度等进行精确计算,数学的运用已初现端倪。到了14世纪,意大利出现了世界上最古老的保险单,标志着现代保险制度的诞生。此后,随着海上贸易的蓬勃发展,保险业务不断拓展,对风险评估和保费计算的要求也越来越高,1654年,数学家帕斯卡(PASCAL)和费马(FERMAT)奠定了概率论的基础,为风险量化提供了理论基础,到了18世纪,精算科学逐渐发展起来,也成为保险的核心工具,数学在保险中的作用日益凸显。
研究保险与数学的关系具有重要的现实意义。从宏观层面看,保险是金融体系和社会保障体系的重要组成部分,其稳定运行对于经济发展和社会稳定至关重要。数学作为一种精确的工具,能够帮助保险公司准确评估风险,合理制定保费,从而保障保险市场的健康有序发展。从微观层面看,对于保险公司而言,精准的数学计算有助于提高风险管理水平,降低经营成本,增强市场竞争力;对于投保人而言,合理的保费定价能够确保其以公平的价格获得相应的保障。
在现代保险领域,数学工具的应用已无处不在。保险公司在核保过程中,需要运用概率论和数理统计的方法,对投保人的风险状况进行评估。例如,通过分析大量的历史数据,计算出不同年龄段、不同职业人群的死亡率、发病率等,以此为依据确定人寿保险的保费。在理赔环节,数学模型可以帮助保险公司快速准确地估算损失金额,提高理赔效率。同时,随着金融创新的不断推进,保险产品日益多样化,如投资连结保险、万能保险等,这些产品的设计和定价需要运用复杂的金融数学模型,以确保产品的公平性和合理性。
据行业数据显示,近年来,随着大数据、人工智能等技术的发展,保险公司对数学工具的依赖程度进一步加深。大数据分析可以挖掘出更多有价值的信息,为风险评估和定价提供更精准的依据;人工智能算法则可以实现自动化核保和理赔,提高业务处理效率。例如,某大型保险公司通过引入先进的数学模型和数据分析技术,将风险评估的准确率提高了20%,理赔处理时间缩短了30%。
总之,保险与数学的千年羁绊源远流长,在现代保险行业中,数学更是发挥着不可替代的作用。深入研究保险的数学基因,对于推动保险行业的创新发展、提升保险服务质量具有重要意义。
二、财产保险:概率论构建的风险管理基石
1.概率论在风险评估中的量化实践
在财产保险中,风险评估是整个业务流程中最关键的一环。而支撑这一环节的,不是靠经验判断或者直觉猜测,而是数学——尤其是概率论,它为我们提供了一套科学、量化的分析工具。
说到风险评估,首先想到的就是历史数据 。这些数据可以说是保险公司最宝贵的资源之一。多年积累下来的灾害记录,比如火灾、洪水、盗窃等事件的发生时间、地点、损失程度等等,构成了一个庞大的数据库。正是通过对这些数据的整理与分析,我们才能从纷繁复杂的现实中找出一些规律。
比如火灾这个话题。大家可能觉得火灾是随机发生的,但如果把几十年甚至上百年的数据放在一起看,就会发现某些地区或时间段确实更容易发生火灾。有些老城区建筑密集、电路老化,火灾频率自然就高;冬季用电取暖频繁,火灾数量也会随之上升。这些看似偶然的事件,一旦放到足够长的时间跨度里,其实是有迹可循的。
有了历史数据还不够,我们还需要一种方法来把这些数据转化为可以预测未来的工具——这就用到了概率模型 。
常见的模型有泊松分布和正态分布。举个例子,如果我们要估算某个城市每年发生火灾的可能性,就可以尝试用泊松分布来建模。前提是假设火灾的发生是相对独立且随机的,那么通过统计过去几十年的数据,就能算出一个大致的概率值。这种模型虽然简单,但在实际应用中非常实用。
再比如损失金额的分布,往往更适合用正态分布来描述。通过对大量历史损失数据进行拟合,我们可以估计未来可能的损失范围,从而为保费定价和准备金预留提供依据。
不过,光靠传统数据已经不能满足现代保险的需求了。随着技术的发展,我们现在能接触到的数据种类越来越多,也越来越大——这就是大数据的作用 。
除了传统的保单和理赔数据,现在还可以结合气象数据、地理信息、社交媒体动态,甚至是实时监控信息来做更精细的风险评估。比如评估洪水风险时,如果我们知道某地近期降雨量激增,再加上地形低洼、排水系统老旧,那这个地方发生洪灾的可能性就会显著上升。这些多维度数据的融合,让我们的风险预测变得更加精准。
为了说明不同灾害之间的差异,请看以下简单的对比案例:
| 灾害类型 | 地区 | 历史数据年限 | 发生次数 | 概率估算结果 |
| 火灾 | A市 | 过去100年 | 50次 | 年均约0.5% |
| 洪水 | B县 | 过去20年 | 30次 | 年均约1.5% |
| 盗窃 | C小区 | 过去5年 | 20次 | 年均约4% |
表一:不同灾害类型的概率估算结果表
可以看到,不同类型、不同地区的灾害概率差异非常明显。对于保险公司来说,这些数字不仅仅是统计数据,更是制定保险费率和风险管理策略的重要依据。比如在高风险区域,适当提高保费是合理的;同时也可以建议客户加强防范措施,比如安装报警系统、改善排水设施等,从源头上降低风险。
总的来说,概率论不仅是理论上的工具,在财产保险的实际操作中,它已经成为不可或缺的一部分。通过历史数据分析、概率模型的应用,以及大数据的支持,保险公司得以更准确地理解风险,并据此做出科学决策。这不仅保障了公司的稳健运营,也为投保人提供了更有针对性的风险保障。
2.大数法则与精算模型的协同作用
在财产保险的实际运作中,大数法则与精算模型之间的配合可以说是保险公司稳健经营的核心支撑之一。
我们都知道,大数法则是概率论中的一个基本原理,它揭示了一个非常重要的现象:当随机事件发生的次数足够多时,其结果的平均值会趋于稳定。这听起来有点抽象,但放在保险领域就变得非常具体了。
举个例子来说,假设一家保险公司承保了10,000份房屋保单。每一份保单都可能因为火灾、洪水、地震等风险而发生损失。如果只承保几十份甚至几百份保单,那么某一次严重的灾害就可能导致赔付金额剧烈波动,影响公司财务稳定。但一旦保单数量增加到上万份,虽然每一户的风险依然存在,整体的赔付情况反而会变得更可预测——这就是大数法则的魅力所在。
具体来看,大数法则对保险业务的影响主要体现在两个方面。
首先,它帮助保险公司更准确地预测未来的赔付水平。通过分析大量的历史数据,我们可以大致估算出某种类型的风险发生的概率以及平均损失金额。比如,在房屋保险中,我们可以通过过去几年的数据来判断火灾发生的频率和平均损失。而当保单数量足够多时,实际发生的火灾数量和损失金额就会接近这些预期值,从而让保险公司能提前做好资金安排。
其次,大数法则也在一定程度上降低了不确定性。不确定性是保险行业最大的挑战之一。如果赔付波动太大,不仅会影响利润,甚至可能威胁公司的生存。而通过扩大承保范围,保险公司可以将个别高额赔付的影响“摊薄”,从而实现更加稳定的运营。这种机制就像是一种“风险稀释剂”。
当然,光靠大数法则是不够的。这时候就需要精算模型来“接手”了。
精算模型本质上是对风险进行量化管理的工具。它的核心参数包括损失分布和准备金计算等内容。以损失分布为例,它是根据历史数据和风险评估结果构建出来的,描述了不同损失金额出现的可能性。比如,通过对过去火灾损失的统计,我们可以知道大多数损失集中在某个区间,极小部分可能会造成巨大损失。有了这样的分布信息,精算师就可以计算出在不同置信水平下可能出现的最大损失,并据此制定相应的风险管理策略。
准备金的计算则直接关系到保险公司的偿付能力。简单来说,准备金就是为未来可能发生的赔付预留的资金。在10,000份房屋保单的例子中,精算师需要综合考虑损失分布、保险费率、时间价值等因素,来确定合理的准备金规模。既不能留得太多,影响资金使用效率;也不能留得太少,导致赔付压力过大。
可以说,大数法则提供了理论基础,而精算模型则是这一理论在实践中落地的工具。两者相辅相成,共同保障了财产保险业务的稳健运行。尤其是在面对自然灾害频发、风险日益复杂的今天,这种数学与金融结合的机制显得尤为重要。
三、人寿保险:寿命预测中的数学密码
1.经验生命表与寿命分布模型
在人寿保险领域,想要科学地评估风险、制定合理的保费标准,光靠经验和直觉是远远不够的。真正起作用的,其实是那些隐藏在背后的数学模型和统计工具。比如经验生命表和寿命分布模型,它们就像是保险公司理解死亡风险的“望远镜”,让我们能够更清楚地看到不同年龄段人群的风险差异。
先来说说经验生命表。这其实是一张表格,记录了不同年龄、性别甚至地区的人群在一年内死亡的概率。这些数据不是凭空捏造的,而是基于大量人口统计数据整理出来的结果。
比如一个60岁的男性,年死亡率大约是1%。也就是说,在100个同龄男性中,大概每年会有1个人去世。而一个20岁的年轻人,年死亡率可能只有0.1%,低了一个数量级。这种差距主要是因为随着年龄增长,身体机能逐渐下降,各种慢性病、突发疾病的风险也随之上升。
不过,经验生命表虽然直观,但它更像是“过去的数据总结”。如果我们想预测未来某个人能活多久、死亡风险如何变化,那就需要引入寿命分布模型 了。
其中最经典的模型之一就是Gompertz模型 。这个模型最早是由19世纪的一位英国精算师本杰明·贡培兹(Benjamin Gompertz)提出的。他观察到一个非常有意思的现象:婴儿期死亡率很高,但随后迅速下降,到了青春期时达到最低点;之后,死亡率开始指数式上升,差不多每十年翻一倍。也就是说,25岁人的死亡概率是15岁时的两倍,35岁又是25岁的两倍,以此类推,直到大约80岁为止。
这个规律不仅适用于现代人,也适用于历史上不同时期的不同国家,甚至一些动物身上也能看到类似趋势。因此它被称为“死亡率定律”。
Gompertz模型的基本形式是:
m(x) = B × Cx
其中m(x)表示年龄为x时的死亡率,B和C是常数。
简单来说,它告诉我们:年龄越大,死亡率越高,而且是呈指数增长的。
那么,这个模型具体怎么用呢?我们可以来看看它的输入和输出:
输入:
历史数据 :这是建模的基础。保险公司需要收集大量人口死亡数据,包括不同性别、年龄、地区的死亡人数和存活人数等。数据的时间跨度通常很长,几十年甚至上百年,这样才能反映长期趋势。
统计分析 :有了数据之后,还需要清洗、处理、拟合。我们会用最大似然估计、最小二乘法等方法来确定模型参数,确保模型尽可能贴近真实情况。
输出:
预期寿命 :这是模型的重要输出之一。它指的是一个人在某个年龄下,平均还能活多少年。例如根据Gompertz模型计算,一个60岁男性的预期寿命可能是20年。
死亡概率分布 :模型还会给出各个年龄段的死亡概率分布。这对保险公司来说非常重要,因为它直接影响到保费定价。如果发现某个年龄段死亡率突然上升,就需要对相关产品进行调整。
除了Gompertz模型,还有其他一些常用的寿命分布模型,比如Makeham模型和Weibull模型。
Makeham模型 是在Gompertz的基础上做了扩展,考虑了除年龄之外的其他恒定风险因素,比如环境、遗传等。
Weibull模型 则更适合描述某些特定类型的寿命分布,比如某些疾病的发病过程,在部分健康险或重疾险中也有应用。
总的来说,经验生命表和寿命分布模型相辅相成:前者提供了直观的死亡率数据,后者则通过数学建模揭示了背后的变化规律。正是这些工具,让保险公司能够更科学地评估风险,设计出更合理的保险产品。
2.现值计算与长期保单设计
接下来我们聊聊长期寿险中的现值计算 。这听起来有点抽象,但其实它关系到每个人买保险时都会关心的问题:我要交多少钱?我能拿回多少?
举个例子,一位50岁的男性购买了一份30年的保障型寿险,保额是50万元。那保险公司要收多少保费才合理?这就需要用到贴现率 和时间价值 的概念了。
我们知道,今天的一笔钱和未来的同样金额并不是等价的。因为钱是可以投资增值的。比如,如果你现在有10万元,存银行或者投资理财,过几年可能变成12万、15万。所以,未来的赔付金额需要用贴现的方式折算成现在的价值 。
公式很简单:
PV = FV / (1 + r)n
其中PV是现值,FV是未来值,r是贴现率,n是年数。
假设20年后要赔付¥10万元,贴现率为5%,那这笔钱现在的价值就是:
PV = 100,000 / (1 + 0.05)20 ≈ ¥37,688.95
也就是说,保险公司只需要准备约¥3.77万元,就可以满足20年后的¥10万元赔付需求(假设资金可以以5%的年利率投资增值)。
对于这位50岁男性来说,30年保障期意味着保险公司要提前做好资金安排。如果贴现率高,未来赔付的现值就低,保费就可以适当降低;反之,如果贴现率低,未来赔付成本更高,保费也会相应提高。
另外,大多数客户不会一次性缴纳所有保费,而是选择分期支付,比如每年付一次。这时候就要考虑时间价值在保费分期中的影响 。
比如这位客户每年缴¥5000元,30年总共是¥15万元。但如果考虑到复利效应,第一年交的钱实际上在30年内会不断增值,而最后一年交的钱就没有那么多增值空间了。
因此,保险公司在设计保费方案时,不仅要考虑死亡率、预期寿命,还要结合市场利率、投资回报等因素,综合测算出一个既能覆盖风险,又能让客户接受的保费水平。
3.随机过程与动态风险评估
前面讲的是静态的风险评估,但在实际操作中,风险是动态变化的。比如一个人年轻时很健康,但随着年龄增长,可能会患上重疾,甚至死亡。为了更准确地捕捉这种动态变化,保险公司会使用一种叫随机过程建模 的方法。
最常用的一种模型是“马尔可夫链模型” 。它的核心思想是:未来的状态只与当前状态有关,与过去无关 。这听起来有点像“人生没有回头路”。
在人寿保险中,我们可以把人的生命状态分为三种:生存、死亡、重疾 。随着时间推移,个体的状态可能会发生转移。比如从“生存”变成“重疾”,再变成“死亡”。
通过对大量历史数据的分析,我们可以估算出不同年龄段下,从一种状态转移到另一种状态的概率。比如,40岁的人在未来一年内继续生存的概率是99.4%,变成重疾的概率是0.5%,死亡的概率是0.1%。
这种模型可以用流程图来展示:
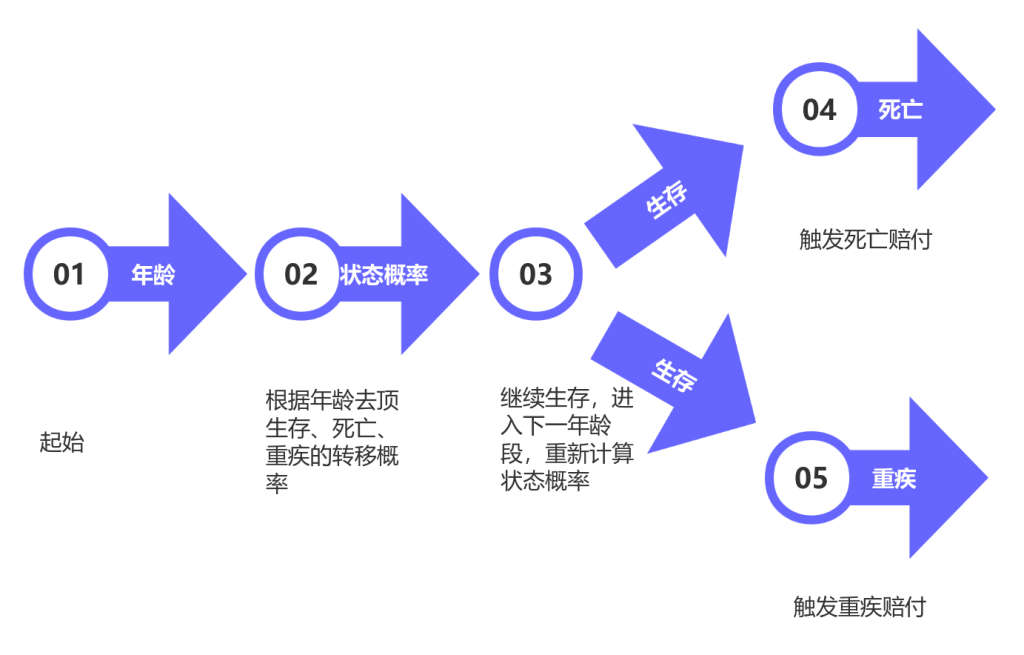
图一:人的生命状态马尔可夫链流程图
通过这样的模型,保险公司可以在不同的时间节点上,动态评估被保险人的风险水平,并据此调整产品的设计。
特别是对于有些寿险公司允许被保险人在确诊重大疾病时,提前领取部分或全部保险金,也就是提供“提前赔付条款”,这个模型特别有用,保险公司可以根据模型预测该客户未来患重疾的可能性和时间点,从而合理设定赔付比例和条件。
人寿保险看似是一种金融产品,但实际上它背后依赖着强大的数学工具支持:
经验生命表帮助我们了解死亡率;
寿命分布模型揭示了寿命变化的规律;
现值计算让我们更科学地评估资金的时间价值;
随机过程建模则帮助我们在动态变化中把握风险。
正是这些工具的协同作用,使得保险公司能够在风险可控的前提下,设计出既符合市场需求又能实现盈利的产品。
四、货运保险:海洋贸易中的概率护航
在货运保险这个领域,想要科学地制定保费标准、设计合理的保障条款,光靠经验判断远远不够。真正起作用的,其实是那些隐藏在背后的风险模型和统计工具。
比如,我们经常说某条航线“比较危险”,但到底有多危险?这种“危险”能不能量化?怎么根据它来调整保费?这就需要我们对航线风险进行概率画像 。
1、航线风险的概率画像
所谓“画像”,其实就是在大量历史数据的基础上,给每一条航线画出一张“风险地图”。这张地图告诉我们:这条航线遇到风暴的可能性有多大?遭遇海盗的概率是多少?出现机械故障的可能性高不高?
这些数据不是凭空想象出来的,而是保险公司长期积累并分析的结果。
自然灾害风险:风暴与海啸
以风暴为例,在北大西洋这样的飓风多发区,过去几十年的历史气象数据显示,每年平均会发生大约10次风暴。那这条航线每天遭遇风暴的概率就是 10 ÷ 365 ≈ 2.7%。
虽然听起来不高,但如果一艘船在这片海域航行几十天,累积下来的风险就不容忽视了。
至于海啸,虽然发生频率远低于风暴,但一旦发生后果极其严重。如果某条航线靠近板块交界带,历史上又多次发生引发海啸的地震,那么这条航线的风险值就会显著上升。
人为风险:海盗与机械故障
再来看看海盗。像亚丁湾、索马里附近海域,是海盗活动的重灾区。据统计,这里每年大约发生20起海盗袭击事件,而每年经过这里的船只超过1万艘。换算一下,每艘船遭遇海盗袭击的概率大概是 20 ÷ 10000 = 0.2%。
虽然这个数字看起来很小,但考虑到单次袭击可能造成巨大损失,保险公司仍然会把它作为重要风险因素来考虑。
至于机械故障,这跟船舶的年龄、维护情况密切相关。老旧的船只设备老化,出问题的概率更高;新船则因为制造工艺先进、检测严格,相对更可靠。
不同航线之间的风险差异是非常明显的。比如:
| 航线名称 | 风暴概率 | 海啸概率 | 海盗概率 | 机械故障概率 |
| 航线A(北大西洋) | 1% | 0.1% | 0.05% | 0.5% |
| 航线B(亚丁湾) | 0.5% | 0.01% | 0.2% | 0.3% |
| 航线C(地中海) | 0.2% | 0.001% | 0.01% | 0.2% |
表二:不同航线风险差异概率表
通过这样的对比,保险公司就能根据不同航线的风险水平,制定相应的费率策略。高风险航线保费自然要贵一些,低风险航线则可以适当降低价格吸引客户。
同时,航运公司也能据此优化航线选择,尽量避开高风险区域,降低运营成本和潜在损失。
2、贝叶斯统计的动态调整机制
不过,风险并不是一成不变的。有时候,新的信息会出现,比如天气突变、海盗活动异常活跃,这时候就需要一种能“实时更新”的方法来调整我们的风险判断。
这就是贝叶斯统计的作用。
简单来说,贝叶斯统计就像是一个“不断学习的系统”。它把我们已有的认知(也就是历史数据)当作起点,然后结合最新的情报(比如天气预警、海盗活动报告),重新计算当前的风险概率。
举个例子:
假设某条航线原本的海盗袭击概率是0.2%。但最近收到情报,说有新的海盗团伙出现在该海域。根据以往经验,在有新团伙活动的情况下,发生袭击的概率为80%。而这类团伙出现的概率本身是5%。
根据贝叶斯公式:
P(A∣B)=P(B)P(B∣A)/P(A)
代入数据:
P(袭击∣新团伙)=(0.8×0.002)/0.05=0.032
也就是说,在新的情报下,海盗袭击的概率从原来的0.2%一下子升到了3.2% 。
这种变化直接影响保险公司的决策:
如果风险上升,就提高保费或增加免赔额;
如果风险下降,就可以适当降低保费,或者放宽保障条件。
通过这种方式,保险公司能够更加灵活地应对不断变化的外部环境,既保护自身利益,也更好地服务客户。
3、极端损失与再保险策略
当然,除了日常的小风险,保险公司最怕的还是那种“低概率但高损失”的极端事件,比如大型海难事故。
这类事件虽然不常发生,但一旦发生,可能直接导致数百万甚至上千万的赔付。为了应对这种情况,保险公司通常会采取再保险策略 。
再保险其实就是“保险的保险”——保险公司把自己承担的一部分风险转移给其他更大的保险公司,从而减轻自己的压力。
损失分布模型的应用
在制定再保险策略之前,我们需要先了解:在各种可能的损失中,哪些是最有可能发生的?哪些属于极端情况?
我们可以用损失分布模型来预测。比如广义帕累托分布(GPD),它专门用来描述那些“小概率但大损失”的事件。
假设我们将损失分为几个区间:
| 损失区间 | 概率 |
| $0 – $1,000,000 | 90% |
| $1,000,001 – $5,000,000 | 9% |
| $5,000,001 – $10,000,000 | 1% |
表三:损失区间概率表
可以看出,大部分损失集中在小额区间,但极少数情况下也会出现巨额损失。这些“尾部风险”虽然概率低,却不能忽视。
再保险分担比例的计算
以一次价值1000万元的海难风险为例:
保险公司自己最多能承受200万元的损失;
那么剩下的800万元,就可以通过再保险的方式转移出去;
这意味着,再保险的分担比例是80%。
当然,再保险公司也不是免费帮忙的,他们会根据风险大小收取一定费用。保险公司需要在“控制风险”和“控制成本”之间找到平衡点。
总之,货运保险的背后,其实是一套精密的数学体系:
通过对历史数据的分析,我们能够对不同航线进行风险画像 ;
利用贝叶斯统计 ,我们可以动态调整风险评估,及时应对突发情况;
借助损失分布模型和再保险策略 ,我们又能有效分散极端风险,确保财务稳定。
正是这些工具的协同作用,使得货运保险能够在复杂多变的环境中保持稳健运行。
五、信用保险:违约不确定性的数学破解
在信用保险这个领域,想要科学地定价、合理控制风险,光靠经验和直觉是远远不够的。真正起作用的是那些背后支撑决策的数据模型和数学工具。
其中,违约概率(PD)的估算 就是整个信用风险管理的核心之一。它不是凭空猜测出来的,而是基于历史数据、财务分析和市场环境等多个维度综合判断的结果。
1、违约概率(PD)的多维度估算
先说说历史数据 。这是最基础也是最重要的参考依据。保险公司会收集大量客户的违约记录,建立起庞大的数据库。这些数据包括客户所属行业、经营年限、过往信用表现等信息。
比如某个行业,经过多年的统计发现,企业年平均违约概率大概是3%。那如果有一家新公司刚进入这个行业,又没有太多额外信息可以参考,我们就可以暂时用这个3%作为初步估计值。
不过,只看历史数据显然还不够深入。这时候就要引入财务分析 来进一步评估。
通过分析企业的资产负债表、利润表、现金流量表等财务报表,我们可以更清楚地了解它的偿债能力和财务健康状况。例如:
如果一家企业的资产负债率高达70%,而且连续两年净利润为负,那它的财务压力就比较大了,违约风险也相应上升;
相反,如果一家企业现金流充足、负债率低,那么它的还款能力就更有保障,违约概率自然也会更低。
举个例子,某家企业虽然属于一个整体违约率较低的行业,但由于自身经营问题,实际违约概率可能已经上升到了5%甚至更高。这说明,不能只看行业平均水平,还要结合企业自身的财务状况做具体分析 。
还有一个不可忽视的因素是市场状况 。宏观经济的变化、行业竞争态势、政策调整等,都会对企业的经营产生影响。
比如在经济下行时期,市场需求减少,很多企业的销售额和利润都会受到冲击,违约概率普遍会上升;而在经济向好时,企业更容易维持稳定运营,违约概率自然就会下降。
此外,不同类型的客户之间也存在显著差异。老客户因为有长期合作记录,保险公司对其信用状况比较了解,评估起来相对容易;而新客户由于缺乏历史数据,风险评估难度更大,通常会被认为违约概率更高。
举个简单的对比:
| 客户类型 | 违约概率 |
| 老客户(信用良好) | 2% |
| 新客户(无信用记录) | 5% |
表四:不同客户违约概率表
为了帮助理解这些因素的影响权重,我们可以用雷达图来做一个形象化的展示:

图二:违约概率(PD)的多维度估算
从这个权重分布可以看出,财务分析在整个PD估算中占据了最大比重,其次是历史数据,再次是市场环境和客户类型。
也就是说,PD的估算并不是单一维度的判断,而是一个需要综合考虑多个因素的过程 。
2、预期损失(EL)的组合管理
有了PD之后,接下来要解决的问题是:如果客户真的违约了,保险公司会损失多少?这就涉及到了另一个关键指标——预期损失(Expected Loss, EL) 。
EL的计算公式很简单:
EL = PD × LGD
其中:
PD 是违约概率;
LGD 是违约损失率,也就是一旦违约发生,保险公司预计会损失的比例。
举个应收账款保险的例子:
假设某企业的违约概率是2%(PD=0.02),一旦违约,保险公司预计会承担80%的损失(LGD=0.8)。那么该笔业务的预期损失就是:
EL = 0.02 × 0.8 = 0.016,即1.6%
这意味着,从长期来看,每承保一笔这样的应收账款,保险公司平均会损失1.6%的金额。
但光看预期损失还不够。保险公司要考虑的还有运营成本和利润空间 。
比如,运营成本率是10%,利润目标是5%。那最终的保费就不能只是覆盖1.6%的预期损失,还要加上这两部分:
成本部分:1.6% × 10% = 0.16%
利润部分:1.6% × 5% = 0.08%
所以总保费费率就是:
1.6% + 0.16% + 0.08% = 1.84%
当然,保险公司不会只承保一个客户,而是会同时面对多个客户。这就涉及到组合管理 的问题。
不同的客户有不同的PD和LGD,把它们组合在一起,就能起到分散风险的作用。比如:
有些客户违约概率高,但LGD低;
有些客户违约概率低,但LGD高;
还有一些客户两者都比较适中。
只要这些客户之间的违约风险不是高度相关,那么整体的风险波动就会更小,组合也就更稳定。
保险公司还会根据客户的信用评级、行业特征等因素,采取差异化管理策略:
对信用好的客户,给予一定的费率优惠;
对风险高的客户,适当提高保费或加强审核; 这样既能吸引优质客户,也能通过高保费弥补潜在的损失。
3、信用 VaR 与组合风险分散
除了EL之外,保险公司还需要关注一个更宏观的风险指标——信用VaR(Value at Risk) ,也就是在一定置信水平下,投资组合可能面临的最大损失。
比如设定95%的置信水平,意味着在正常市场条件下,有95%的概率,组合的损失不会超过某个上限。剩下的5%则是极端情况下的风险敞口。
以一个总价值为1000万美元的投资组合为例,经过一系列统计建模和模拟计算,得出其95%置信水平下的VaR为50万美元。也就是说,未来一段时间内,组合的最大损失大概率不会超过50万美元。
计算信用VaR的过程主要包括以下几个步骤:
首先,需要对每个客户的违约风险进行评估,确定其PD和LGD。然后,考虑客户之间的相关性,因为不同客户的违约情况可能相互影响。如果某些客户处于同一行业或地区,它们的违约风险可能具有较高的相关性。例如,在房地产行业不景气时,该行业内的多个企业可能同时面临违约风险。通过使用多元统计模型,如Copula模型,可以更好地描述客户之间的相关性。最后,根据这些信息,运用蒙特卡罗模拟等方法,模拟出投资组合在不同情景下的损失分布,从而确定在95%置信水平下的最大可能损失。 行业和地区相关性对风险集中有着显著影响。当多个客户集中在同一行业或地区时,一旦该行业或地区出现不利情况,如经济衰退、政策调整或自然灾害等,这些客户的违约概率可能会同时上升,导致风险集中。例如,某地区的制造业企业,如果该地区遭遇严重的环境污染问题,政府加强环保监管,这些企业可能面临生产受限、成本上升等问题,违约风险大幅增加。此时,投资组合的损失可能会远远超过预期。
客户之间的违约相关性 可以用散点图来直观表示。如果两个客户的违约行为高度正相关,图上的点会呈现出一条斜向上的趋势;如果是负相关,则趋势相反;如果没有明显关系,点就会随机分布。
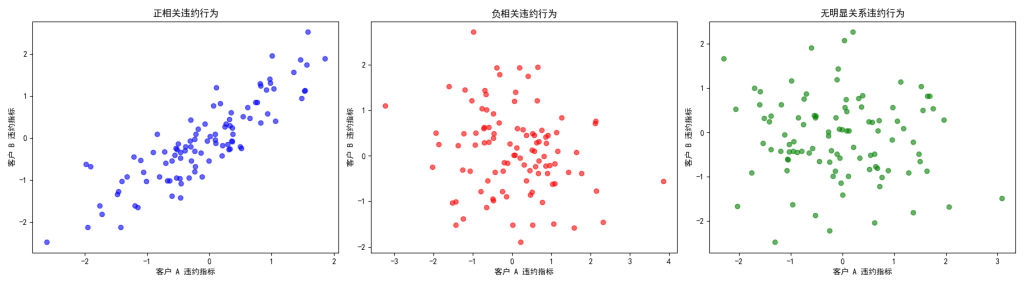
图三:客户之间违约相关性散点图
这种可视化方式有助于快速识别哪些客户之间存在风险集中问题。
为了降低风险集中,保险公司可以采取组合风险分散策略。通过将投资组合分散到不同行业、不同地区的客户中,可以减少行业和地区相关性对风险的影响。例如,同时承保制造业、服务业、农业等多个行业的客户,以及不同地区的企业,使得投资组合的风险更加分散。这样,即使某个行业或地区出现问题,其他行业或地区的客户可能仍然保持稳定,从而降低整个投资组合的损失风险。 信用VaR为信用保险投资组合的风险评估提供了量化工具,而组合风险分散策略则有助于降低风险集中,保障保险公司的财务稳定。通过合理运用这些方法,保险公司能够更好地管理信用风险,实现可持续发展。
六、责任保险:法律风险的概率管控
在责任保险这个领域,想要科学地制定保费标准、设计合理的保障条款,光靠经验判断远远不够。真正起作用的,其实是那些隐藏在背后的风险模型和统计工具。
比如,我们经常说某类职业或某个行业“比较危险”,但到底有多危险?这种“危险”能不能量化?怎么根据它来调整保费?这就需要我们对不同行业的事故概率进行系统性评估。
1、事故概率的行业化评估
先来看看最常见的几个行业,它们各自面临的责任事故风险有多大?
医疗行业:一个高风险的职业场景
医生的工作直接关系到患者的生命健康,任何细微的差错都可能引发严重后果。例如误诊、手术失误、药物不良反应等。
据统计,医疗行业的手术失误率大约为0.3%,药物不良反应导致的事故概率约为0.2%。综合起来,医疗行业的责任事故概率大概在0.5%左右。
虽然这个数字看起来不高,但由于涉及生命安全,一旦发生事故,影响往往非常大。
教育行业:相对低风险,但也不能掉以轻心
教师主要负责教学和学生管理工作,责任事故通常表现为学生在校期间意外受伤等情况。
随着校园安全管理措施不断完善,教育行业的责任事故概率已经降到很低水平,大约只有0.1%。但这并不意味着可以完全忽视,尤其在体育课、实验课等高风险环节中,仍需加强防范。
化工行业:环境因素带来的高风险
化工企业所处的生产环境通常涉及到易燃易爆、有毒有害的化学物质。如果温度、压力控制不当,就容易发生泄漏、爆炸等事故。
据相关数据显示,化工行业的责任事故概率大约为1%。这类事故一旦发生,后果往往非常严重,不仅会造成人员伤亡,还可能带来环境污染等连锁问题。
相比之下,金融行业的办公环境主要是办公室,风险集中在信息安全和金融诈骗方面,受物理环境影响较小,责任事故概率大约为0.05%。
建筑行业:设备操作带来的风险不容忽视
建筑行业大量使用起重机、挖掘机等机械设备,这些设备的操作复杂,对人员技能要求很高。
如果设备维护不到位或者操作不当,就容易引发安全事故。例如钢丝绳磨损未及时更换,可能导致重物坠落,造成人员伤亡。
建筑行业的责任事故概率约为0.8%。而在电子信息行业,主要使用计算机、服务器等设备,设备故障一般不会造成严重人身伤害,责任事故概率约为0.2%。
下面是几个典型行业的事故概率对比表:
| 行业类型 | 事故概率 | 主要事故类型 |
| 医疗行业 | 0.5% | 误诊、手术失误、药物不良反应 |
| 化工行业 | 1% | 泄漏、爆炸、中毒 |
| 建筑行业 | 0.8% | 坍塌、坠落、机械伤害 |
| 教育行业 | 0.1% | 学生意外受伤 |
| 金融行业 | 0.05% | 信息安全事故、金融诈骗 |
| 电子信息行业 | 0.2% | 设备故障、系统瘫痪 |
表五:典型行业事故概率对比表
通过这张表格可以看出,职业、环境、设备等因素对责任事故概率的影响非常明显。
保险公司可以根据这些差异,为不同行业制定更有针对性的保险方案,合理设定费率;同时,各行业也可以根据自身情况,采取预防措施,降低事故发生率。
2、极端值理论(EVT)的应用场景
除了日常的小风险,保险公司最怕的是那种“低概率但高损失”的极端事件,比如化工企业的重大环境事故。
这类事件虽然不常发生,但一旦发生,可能直接导致数百万甚至上千万的赔付。为了应对这种情况,保险公司通常会借助一种叫”极端值理论(EVT)“的数学工具。
EVT专门用于研究数据的“尾部特征”,也就是那些极端小概率但影响巨大的事件。传统的概率分布模型在描述这类事件时往往表现不佳,而EVT能更准确地预测极端事件的发生概率和损失规模。
举个例子,假设一家化工企业可能发生一次高达1000万元的环境事故。虽然发生的可能性极低,但一旦发生,对企业和保险公司都是沉重打击。
EVT常用的预测方法有两种:
块最大值法(Block Maxima, BM) :把历史数据按时间段划分,取每段时间的最大值作为样本,用广义极值分布(GEV)进行拟合;
超阈值法(Peaks Over Threshold, POT) :选择一个合适的阈值,只分析超过该阈值的数据,用广义帕累托分布(GPD)建模。
在化工行业,POT方法更为常用,因为它能更充分地利用数据信息,对极端事件的预测也更准确。
举个实际应用的例子:
保险公司收集了这家化工企业多年的事故损失数据,设定了一个阈值,比如100万元。然后提取所有超过这个金额的损失数据,用GPD模型进行拟合,从而计算出发生1000万元环境事故的概率。
这种预测方法可以帮助保险公司提前做好准备,合理设定保费,并通过再保险等方式分散风险。
3、共险模型与风险组合优化
说到风险分散,还有一个非常重要的工具——Copula模型 ,它主要用于分析多个风险之间的相关性。
特别是在一些流程相似度高的行业中,比如医疗机构,不同医院之间可能存在相同的麻醉流程、消毒流程等。如果某一批次的麻醉药物存在质量问题,可能会导致多家医院同时出现患者不良反应事件。
这时候,Copula模型就能帮助我们量化这些机构之间的风险相关性,从而更准确地评估整体风险。
基于Copula模型,保险公司可以进行风险组合优化 :
将不同行业、不同风险来源的业务组合在一起;
利用它们之间的低相关性,降低整体风险波动;
减少因某一行业集中风险而导致的巨额赔付。
比如,同时承保医疗机构、建筑企业和金融机构的责任保险,由于这些行业的风险机制不同,它们之间的相关性较低,组合之后整体风险会更加稳定。
更重要的是,合理的风险组合还能减少保险公司所需的资本和准备金规模。当风险分散在多个不同的业务中时,整体波动性下降,就不需要预留过多资金应对极端情况,资金使用效率大大提高。
下面是用树状图展示的风险分散路径示意图:
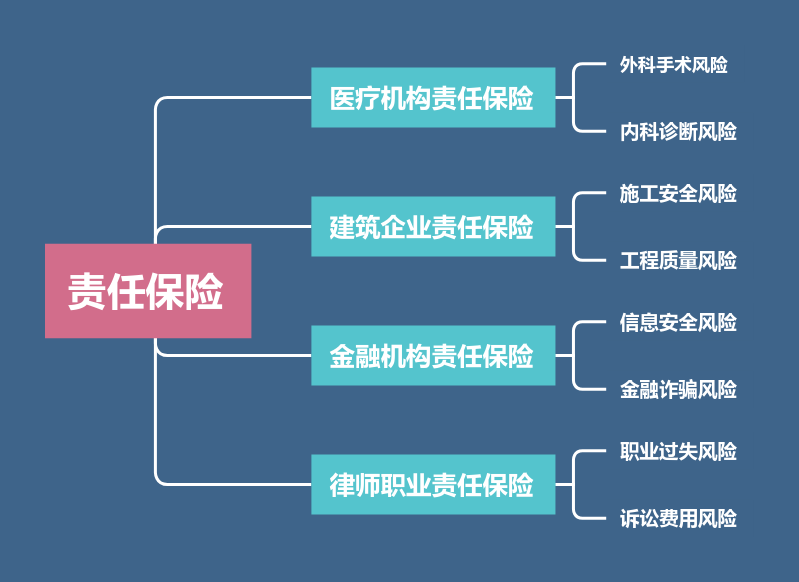
图四:职业责任保险风险分散树状图
通过这种结构化的风险分散方式,保险公司可以在控制风险的同时,提升业务的可持续性和盈利能力。
责任保险的背后,其实是一套精密的数学体系:
不同行业的事故概率差异显著,职业、环境和设备是主要影响因素;
极端值理论(EVT)让我们能够更好地预测低概率高损失的极端事件;
Copula模型则帮助我们理解风险之间的相关性,实现风险组合的优化。
正是这些工具的协同作用,使得责任保险能够在复杂多变的环境中保持稳健运行。
七、结论:数学基因驱动的保险范式进化与未来展望
从财产保险的风险量化,到人寿保险的寿命预测;从货运保险的动态调整,到信用保险的违约管理,再到责任保险中对极端事件的应对……你会发现,无论走到保险行业的哪个角落,总有一个看不见却无处不在的力量在背后支撑着这一切——那就是数学。
是的,概率论、统计学、精算模型这些看似抽象的工具,其实是保险真正的“基因”。它们不仅帮助我们理解风险,更重要的是,让我们能用科学的方式去衡量它、定价它、管理它。
1、数学:保险从经验走向科学的桥梁
过去,保险很大程度上依赖经验和直觉来做决策。比如:“这片区域火灾多发,保费要贵一些”,或者“这个客户看起来不太靠谱,拒了”。
但今天不一样了。数学为我们提供了一种更严谨、更客观的方式来理解世界。
在财产保险中,“火灾可能发生”变成了“年发生概率为1%”;
在人寿保险里,“寿命不确定”被转化为“60岁男性平均还能活20年”;
在货运保险中,“海盗活动增加”意味着“这条航线的保费需要上浮5%”;
在信用保险中,“客户偿债能力未知”被建模成“违约概率为2%”;
在责任保险中,“环境事故可能”最终体现为“需要预留1000万准备金”。
这些变化不只是数字游戏,而是整个行业从“模糊管理”走向“精准治理”的标志。数学让保险不再只是靠经验判断的行业,而是一个可以用数据说话、用模型决策的现代金融系统。
换句话说,数学不仅是工具,更是保险从“凭感觉”到“讲科学”的核心转变动力。
二、数学赋能:从稳定经营到创造价值
如果说保险最初的功能是“兜底”,那么数学的介入则让它开始具备了“创造价值”的能力。
“大数法则”就像是保险公司的“定海神针”:通过大量分散风险,保险公司能在不确定性中找到稳定性;
“期望值定价模型”(损失概率 × 损失金额)让风险成本变得可计算,既能保障客户,也能保证公司盈利;
“贝叶斯统计”、“随机过程”等动态模型则赋予保险“感知变化”的能力:无论是天气突变影响货运安全,还是客户财务状况变化影响信用评级,都能被及时捕捉并反映在保费或条款调整中。
这种“随环境进化”的能力,不仅增强了保险公司的抗风险能力,也让保险产品变得更加灵活、个性化和高效。
可以说,数学正在推动保险从一个“被动赔付者”向“主动管理者”转型——它不仅能赔,更能赔得准、赔得合理。
3、未来已来:数学 + 新技术 = 保险的新纪元
随着人工智能、大数据、区块链等新技术的发展,保险正在迎来一场新的变革。而在这场变革中,数学依然是那个最关键的“幕后推手”。
大数据和机器学习 带来了前所未有的数据维度:实时天气、物联网传感器、社交媒体情绪……这些信息都可以被整合进风险模型中,让评估从“历史平均”迈向“实时精准”。
量子计算和复杂系统理论的突破,则有望解决传统模型在极端事件中的局限,比如全球金融危机引发的连锁违约,或是气候变化带来的巨灾集群。
区块链和智能合约 的结合,更是让数学模型的输出结果可以直接变成自动执行的规则,减少人为干预,提升效率和透明度。
未来的保险,将不再只是一个“转移风险”的工具,而是一个能够“预防风险”、“优化决策”甚至“创造价值”的智能系统。
我们可以大胆设想:当概率论遇上人工智能,当精算模型拥抱大数据,保险就不再是简单的合同和赔付,而是一个嵌入经济运行、社会管理、个人生活的“数字免疫系统”。
回望保险几百年的演进史,你会发现,真正推动它不断前行的,并不是某一种产品或某个监管政策,而是数学这门古老的学科。数学,是保险的基因,更是保险的“源代码”,也是它持续创新的“引擎”。
站在今天这个节点上看,保险已经不再只是“出事后赔钱”,而是在变得更聪明、更敏捷、更有预见性。而这背后,正是数学在默默发力。
所以,如果你问我:保险的未来会是什么样子?
我会说:那将是一个由数学驱动的世界——一个更科学、更智能、也更有温度的保险新时代。
参考书目:
《风险理论与非寿险精算》,作者:谢志刚、韩天雄,南开大学出版社,2000年9月第一版
《保险精算学》(第2版),作者:王晓军,中国人民大学出版社,1995年12月
《数学风险论导引》,作者:汉斯U.盖伯(瑞士),世界图书出版公司,1997年
《风险管理与保险原理(第十四版)》,作者:乔治·E. 瑞达、迈克尔·J·麦克纳马拉、威廉H·拉伯尔,中国人民大学出版社,2023年
《信用保险理论与实务》,作者:曾鸣,上海财经大学出版社有限公司,2008年
《责任保险理论实务与案例》,作者:张洪涛、王和,中国人民大学出版社,2005年9月
《概率论与数理统计(第四版)》,作者:盛骤、谢式千、潘承毅,高等教育出版社,2008年
《应用随机过程》,作者:Sheldon M. Ross,人民邮电出版社,2021年